I’m still quite busy analyzing the large dataset (~1600 cases) collected from the conflict resolution online user study conducted earlier this year. Before delving into detailed model building, and findings related to specific types of normative conflicts, I thought I’d present two simple yet quite clear findings that appeared upon the initial inspection of the data:
1. Which of the five values in the experiment were found to matter the most, in the general sense?
We have asked participants to use a pie chart to indicate, in the general sense, and assuming a role (either a parent or a child), their preference for five human values that we found to matter the most in the location sharing domain. Below was the description we provided for these values.
Friendship: for you, or your family members to build friendships, a social life, and be recognized amongst others in the social circle.
Privacy: for you, or your family members to be free from unwanted outside intrusion, and undesirably shared information.
Safety: for you, or your family members to be free from dangers or harm.
Independence: for you, or your family members to be capable of doing what they need to do without other’s control or support.
Responsibility: for you, or your family members to know and be able to do the tasks they’re expected to do.
The pie chart below shows how, on average, users ranked the importance of these values:
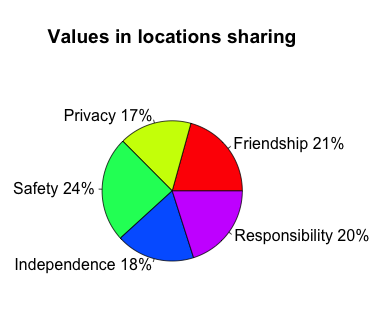
What I find interesting is that (1) the fact that there was a significant preference for some values over others and (2) that privacy, long considered a pivotal value in social data sharing (especially location!), was ranked lowest. Now, the domain of the experiment is indeed family life, so that makes this finding a little less surprising, yet still interesting as privacy ranked last amongst all five values, not just second to safety, the expected winner.
2. Obligations vs. Prohibitions (to share and receive data)?
Throughout the experiment we asked participants to create conflicting normative statements regarding sharing and receiving location, and we then asked them to indicate their preference (and by how much, using a slider), in the case a conflict occurs. Now, a conflict always included an obligation commitment (e.g. I want someone to share/receive data with/from me/somebody else under some circumstances), and a prohibition (e.g. I want someone to not share/receive data with/from me/somebody else under some circumstances). Again, before going into details on predicting user preference using statistical models, another simple yet clear finding presented itself upon early data inspection:
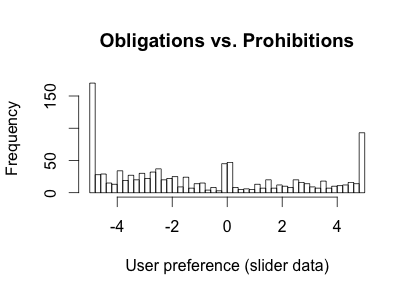
Data here was modified so that all obligations are to the left side (negative values), and all prohibitions are to the right side (positive values). In the experiment itself the order of course was random. We can see that there is a clear tendency for obligations of sharing and receiving data to be preferred to prohibitions. If we make this discrete, obligations were preferred around 63% of the time:
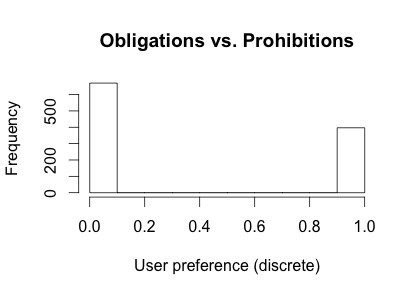
So, and without drawing any detailed conclusion yet, these two simple findings could alone increase prediction accuracy in conflict resolution in location sharing, by quite some margin.





